8. 卷积神经网络推理 (1):Direct 卷积的纯 Python 实现、库函数实现#
公开时间:2022-01-03
备注
该工作是第五届 Ubiquant Challenge 量化新星挑战赛|并行程序设计竞赛的初赛入围相关工作。该工作在【天之孔】队长强宜澄的牵头下完成。
这份文档是原题背景的介绍。原题是使用 Winograd 算法高效实现 \(3 \times 3\) 卷积核神经网络的推理过程;我们将在之后的文档再对原题进行讨论。
在最近 10 年,卷积神经网络 (CNN, Convolutional Neural Network) 在图像识别中取得很大的成功。典型的例子会是 VGG16, ResNet, GoogLeNet。深度卷积网络的模型很大,并且大多数时候在作卷积、池化操作,而较少或只在最后进行多层感知,卷积网络计算时间相对较长。
我们也知道,神经网络方法的学习需要用到反向传播 (BP, Backward Propagation);这是非常重要的议题,它推动了自动导数、机器学习框架的实现与推广。但在实际的应用情景中,更多地是针对已经学习完毕的模型,进行推理计算 (Inference),即网络的正向过程。这种情形可能是手机输入法、信息软件的文字翻译、自动驾驶等等 (或许金融超额收益也是一种情形,但我还不具备理解量化金融的知识 >.<)。它们都要求在获得输入后,以最迅速的方式通过模型计算并给出结果,而这速度经常是以毫秒 (ms) 而非秒 (sec) 为单位。快速的程序实现意味着优质的用户体验、意味着生命的安全、意味着稳定的金钱收益。写一个高效的卷积网络程序至关重要。
拯救生命大挑战!(误
您是 Tezla 的算法实现工程师。您需要高效率编写一个卷积神经网络,使得汽车能自动识别到高速路上是否有小孩横穿。您能否拯救一个充满未来与希望 (但现在不太负责) 的生命?
我们将会分为三份文档,讨论这个问题。
第一份文档中,我们会
简单介绍卷积网络的定义、公式、基础实现,并辅以图像加深理解;
以 Python 为主要编程语言,介绍一些有效的高效率纯 Python 实现方法;
指出并简单测试常用的库函数实现 (oneDNN, PyTorch),以及我们自己编写的 C/C++ 程序的效率;
指出纯 Python 实现的不足,并对效率改进的思路做简单说明。
第二份文档中,我们会
介绍 Winograd 算法[1],并对 \(F(6, 3)\) 情形作纯 Python 实现;
对 Winograd 算法作简单分析;
第三份文档中,我们会
详细介绍初赛工作中基于 x86-64 (允许 AVX-512) CPU 的 C/C++ 优化思路;
对该程序的算法复杂度与调试技巧作说明;
对其它 C/C++ 优化思路做简短说明。
这是应用与实现文档,我们不对卷积网络或 Winograd 算法作原理性的叙述与证明,也不讨论卷积网络的有效性。我们只考察卷积核大小为 \(3 \times 3\) 的情形。
import numpy as np
import numba as nb
import torch
import ctypes, itertools, time
import pandas as pd
torch.set_grad_enabled(False)
np.set_printoptions(6, suppress=True, linewidth=150)
备注
本文档使用的 CPU 是 Intel Xeon Gold 6154。本文档仅使用 8 核并行。
编译环境为 GNU C++ 10.2.0。尽管 Intel C++ (icpc) 也可以编译,但不是很建议。
torch.set_num_threads(8)
文档执行指南
本文档使用 ctypes 链接 C 语言的编译库。若读者需要执行该 Jupyter 笔记本,请不要仅下载该 .ipynb 文件——该文档还需要使用编译后的 C/C++ 代码。读者可以移步到 gitee: ajz34/winograd6x3 下载源代码与 Jupyter 笔记本,并在支持 AVX-512 的机器上使用 cmake 编译。
作为程序实现效率的参比,我们还实现了 Intel oneDNN 下的卷积网络。因此在 cmake 中,我们还引入了 Intel oneAPI 的路径。需要编译 C/C++ 程序的读者可能需要更改该路径。
警告
文档作者当前工作 (计算化学理论的双杂化泛函分支) 与该文档所使用的应用或算法都毫无干系。电子积分、格点积分分支或许会使用到相似的算法思想。文档除了卷积网络本身,大多数知识都是现学的,因此可能会在叙述中存在基本性错误。
但我希望能强调算法与架构在程序设计中的重要性,读者受众应可以是行外人 (因为作者也是外行 2333)。该系列文档的算法绝非是最高效;它只是程序思路相对简单,效率尚可。
对于 Python 语言而言,由于其语言本身的特性,无法达到令人满意的效率。但即使如此,借用合适的库 (NumPy 或 Numba)、调用合适的函数,可以在一定程度上改进效率;甚至可以逼近 C/C++ 程序。这份文档的 Python 实现或许不那么惊艳,但足够表明合适的库与库函数是多么重要。
8.1. 卷积神经网络简介与实现#
8.1.1. 3x3 卷积神经网络定义#
我们先考虑一种特定的、较小型的情形。现在我们要处理一张图片,其参数为
高度 (in height)
IH\(H_\mathrm{in} = 14\);宽度 (in width)
IW\(W_\mathrm{in} = 20\);通道数 (in channel)
IC\(C_\mathrm{in} = 4\)。 高度、宽度是我们立即能理解的。通道对于普通的图片而言,可以是红、绿、蓝 (RGB 3 通道),或青、品红、黄、黑 (CMYK 4 通道)、或黑白 (灰度 1 通道)。但这里所提及的图片是广义上的图片,通道数可以是任意的。
对上述图片进行卷积操作时,需要通过所谓的“卷积核”。卷积核的作用相当于提取输入图像的特征。其参数为
高方向 (kernel height) \(K_\mathrm{H} = 3\)、宽方向 (kernel width) \(K_\mathrm{W} = 3\);我们会说这类卷积核的大小是 \(3 \times 3\),且后续文档仅讨论这类卷积核;
输入通道 (in channel)
IC\(C_\mathrm{in} = 4\),这必须要与输入图片通道数相同;输出通道 (out channel)
OC\(C_\mathrm{out} = 16\)。若熟悉 Photoshop,像图像的色调、亮度、梯度、轮廓等等近邻局域信息都可以是输出;当然,在神经网络中,这些都是将会被学习的隐含量,未必是直观的信息。
由此,输出图片的参数信息就是确定的了:
高度 (out height)
OH\(H_\mathrm{out} = H_\mathrm{in} - K_\mathrm{H} + 1 = H_\mathrm{in} - 2 = 12\);宽度 (out width)
OW\(W_\mathrm{out} = W_\mathrm{in} - K_\mathrm{W} + 1 = W_\mathrm{in} - 2 = 18\);通道数 (out channel)
OC\(C_\mathrm{out} = 16\) 随着卷积核参数固定。
很多时候,如果一次性处理多张图片,程序效率通常会高一些。我们在这里给出分批数量 \(N = 8\)。
图片的储存方式在不同的程序中可能不同。我们所采用的对图片的存储方式是“NCHW”方式,即
输入图片
image\(d_{i,c,x,y}\) 维度 \((N, C_\mathrm{in}, H_\mathrm{in}, W_\mathrm{in})\);输出图片
result\(Y_{i,k,x,y}\) 维度 \((N, C_\mathrm{out}, H_\mathrm{out}, W_\mathrm{out})\)。
卷积核 filtr \(g_{k,c,u,v}\) 的维度在各种程序通常一致,即 \((C_\mathrm{out}, C_\mathrm{in}, K_\mathrm{H}, K_\mathrm{W})\) 即 \((C_\mathrm{out}, C_\mathrm{in}, 3, 3)\)。
N = 8
IH, IW = 14, 20
IC, OC = 4, 16
OH, OW = IH - 2, IW - 2
image = np.random.random(( N, IC, IH, IW)).astype('f') * 255
filtr = np.random.random((OC, IC, 3, 3)).astype('f')
result = np.zeros (( N, OC, OH, OW)).astype('f')
为了简化后续的程序,我们会将输入图像与卷积核放在下述被折叠的代码中,以类 CNNInput 表示,并且给出各种维度信息。
Show code cell content
class CNNInput:
def __init__(self, image, filtr):
self.image = image
self.filtr = filtr
# Dimensions that could be infered from input image and filter
self.N, self.IC, self.IH, self.IW = image.shape
self.OC = filtr.shape[0]
self.OH, self.OW = self.IH - 2, self.IW - 2
# Check sanity for filter dimension
assert(len(filtr.shape) == 4)
assert(self.IC == filtr.shape[1])
assert(filtr.shape[2] == filtr.shape[3])
@property
def dim_result(self):
"""Return expected dimension of output image (as result)"""
return self.N, self.OC, self.OH, self.OW
8.1.2. 卷积网络过程图示、公式与极简 Python 实现#
卷积的过程相当于对每个输出通道 \(k\),将图像分块 \(\boldsymbol{d}\) 与卷积核 \(\boldsymbol{g}\) 作乘积;随后输出一个像素变小了一些的图像 \(\boldsymbol{Y}\)。若卷积核大小是 \(3 \times 3\),则输出图像相对于输入图像,在宽与高上都各少 2 个像素。
下述图片是基于分批数量 \(N = 1\) 绘制;不过我们的程序实现中 \(N = 8\)。
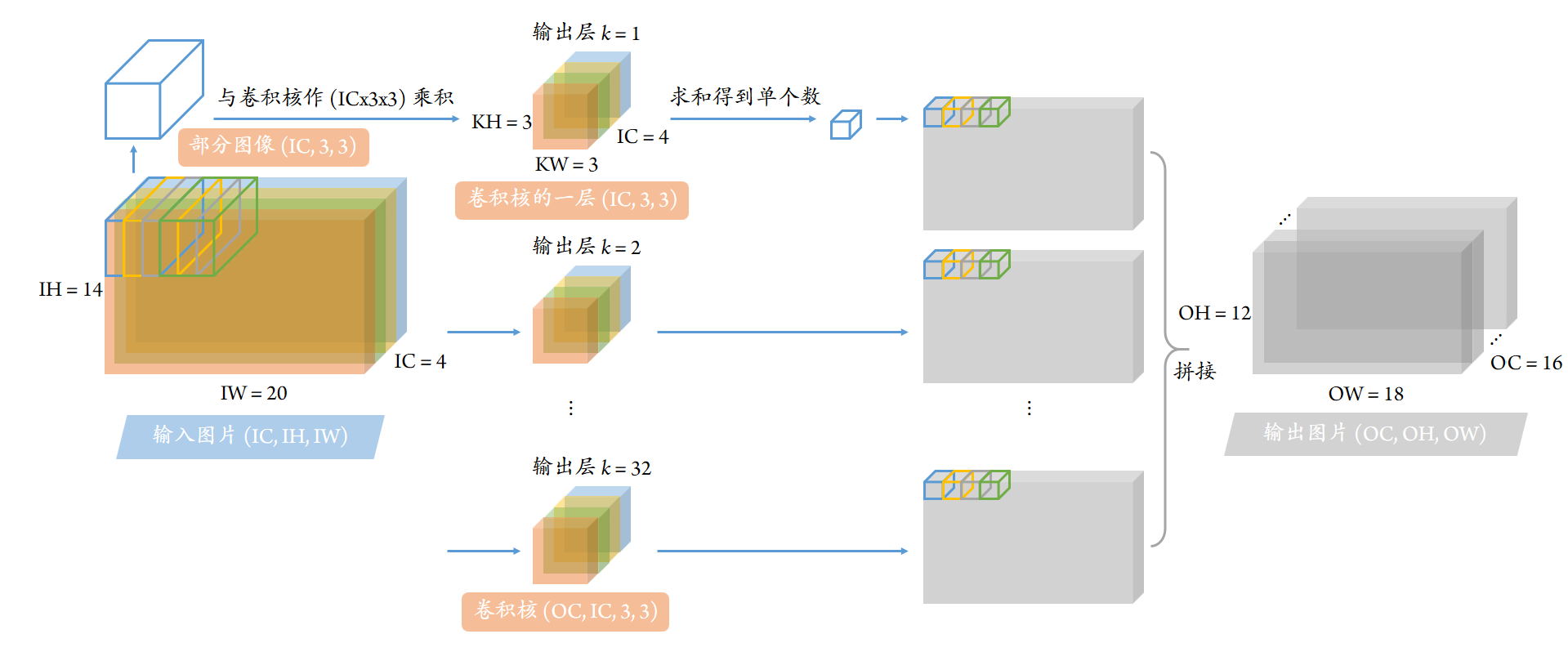
若从公式上来理解,则可以写为
上式中,非求和角标有分批数量 \(i < N\)、输出通道 \(k < OC\)、输入图像像素数 \(x < OH\) 与 \(y < OW\);被求和角标有输入通道 \(c < IC\)、以及卷积核 \(u < KH = 3\) 与 \(v < KW = 3\)。依下述使用 NumPy 程序 conv_direct_python_7loops,利用对所有角标 \(i, k, x, y, c, u, v\) 的七重循环,就可以实现卷积过程。
def conv_direct_python_7loops(image, filtr):
inp = CNNInput(image, filtr)
result = np.zeros(inp.dim_result).astype('f')
for i in range(inp.N): # batch size
for k in range(inp.OC): # out channel
for x in range(inp.OH): # out height
for y in range(inp.OW): # out width
for c in range(inp.IC): # input channel
for u in range(3): # kernel width
for v in range(3): # kernel height
result[i, k, x, y] += image[i, c, x+u, y+v] * filtr[k, c, u, v]
return result
%%timeit -r 7 -n 1
result = conv_direct_python_7loops(image, filtr)
654 ms ± 1.39 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
但 Python 是一种很神奇的语言:它是以 C 作为底层实现的语言。若库函数使用得当,一般来说还是会有比较可观的效率,并且大大简化代码量。首先,注意到 Python 的 for 循环效率是恶名昭著的;它可以通过 itertools 进行改进。在我们测试的机器上,一般有 40 ms 的提升 (但也只有 40 ms)。更关键的是,使用 itertools 可以减少 Python 的强制缩进数,使代码看起来更加友好,行数更少。
def conv_direct_python_7loops(image, filtr):
inp = CNNInput(image, filtr)
result = np.zeros(inp.dim_result).astype('f')
for i, k, x, y, c, u, v in itertools.product(
range(inp.N), range(inp.OC), range(inp.OH), range(inp.OW),
range(inp.IC), range(3), range(3)):
result[i, k, x, y] += image[i, c, x+u, y+v] * filtr[k, c, u, v]
return result
%%timeit -r 7 -n 1
result_ref = conv_direct_python_7loops(image, filtr)
611 ms ± 582 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
看起来这段代码毫无破绽,没有多余的循环、没有多余的浮点计算。真的是这样吗?是也不是。原理上,这句话是对的;但我们马上就会发现,上面这段代码的效率是有多糟糕。
8.2. 纯 Python 性能优化#
8.2.1. 利用 NumPy 减少代码循环数#
我们知道 NumPy 是 Python 中专门对矩阵或张量进行优化的库。如果合理利用 NumPy,可以大大加速程序效率,同时降低代码复杂程度。
但图像卷积问题,麻烦就麻烦它与矩阵计算神似,却并不能直接化为矩阵或张量计算问题。但如果我们不考虑输出像素角标 \(x, y\) (我们把这两个角标放到右上方),那么它就化为了简单的张量数乘与求和运算:
我们可以对 \(i, k, x, y\) 进行显式循环;而剩下的乘积与求和就交给 NumPy 完成。需要指出,整个程序的核心代码仅两行 (Python/NumPy 是真的方便 =ω=)。
def conv_direct_numpy_4loops(image, filtr):
inp = CNNInput(image, filtr)
result = np.empty(inp.dim_result).astype('f')
for i, k, x, y in itertools.product(range(inp.N), range(inp.OC), range(inp.OH), range(inp.OW)):
result[i, k, x, y] = (image[i, :, x:x+3, y:y+3] * filtr[k]).sum()
return result
%%timeit -r 7 -n 7
result = conv_direct_numpy_4loops(image, filtr)
111 ms ± 288 µs per loop (mean ± std. dev. of 7 runs, 7 loops each)
8.2.2. 利用 einsum 张量缩并提升性能#
我们看到了 6 倍左右的效率提升!但上述程序的效率非常低。
借助于强大且直观的 NumPy 张量缩并引擎 np.einsum,我们可以将 (右下角的) 角标缩并顺序写为字符串。计算过程仍然可以在两行之内高效并行地解决 (记得要将 optmize=True 的选项打开),并且清晰地展示了张量缩并的具体过程;但仍然需要对 \(x, y\) 作循环:
def conv_direct_numpy_einsum(image, filtr):
inp = CNNInput(image, filtr)
result = np.empty(inp.dim_result).astype('f')
for x, y in itertools.product(range(inp.OH), range(inp.OW)):
result[:, :, x, y] = np.einsum("icuv, kcuv -> ik", image[:, :, x:x+3, y:y+3], filtr, optimize=True)
return result
%%timeit -r 7 -n 7
result = conv_direct_numpy_einsum(image, filtr)
13.6 ms ± 132 µs per loop (mean ± std. dev. of 7 runs, 7 loops each)
8.2.3. 将问题化简为矩阵乘法#
我们又看到了 6 倍左右效率的提升!尽管 np.einsum 通常可以找到一条最佳的优化路径,但其实现可能是通过 np.tensordot 而非 np.matmul 给出。如果我们注意到卷积可以写成类似于矩阵乘法的形式:
那么实际上,\(c, u, v\) 作为被缩并角标,可以用矩阵乘法处理。这仍然可以在两行代码中完成,但代码可能不是很直观:
def conv_direct_numpy_matmul(image, filtr):
inp = CNNInput(image, filtr)
result = np.empty(inp.dim_result).astype('f')
for x, y in itertools.product(range(inp.OH), range(inp.OW)):
result[:, :, x, y] = image[:, :, x:x+3, y:y+3].reshape(inp.N, -1) @ filtr.reshape(inp.OC, -1).T
return result
%%timeit -r 7 -n 7
result = conv_direct_numpy_matmul(image, filtr)
1.04 ms ± 13.7 µs per loop (mean ± std. dev. of 7 runs, 7 loops each)
但依这个思路,还能有更快的代码。我们注意到卷积核 filtr \(g_{k,cuv}\) 一直被用到,但在迭代过程中始终需要经过转置并压平成为 \((g^\dagger)_{cuv,k}\)。我们可以提前分配额外的内存,卷积核转置到 trans_filtr。当前的问题太小,可能无法体现明显的效率优势。痛心疾首 (sic) 的是,由于转置多了一行代码,因此代码量增加了 50%。
def conv_direct_numpy_matmul(image, filtr):
inp = CNNInput(image, filtr)
result = np.empty(inp.dim_result).astype('f')
trans_filtr = filtr.reshape(inp.OC, -1).T.copy()
for x, y in itertools.product(range(inp.OH), range(inp.OW)):
result[:, :, x, y] = image[:, :, x:x+3, y:y+3].reshape(inp.N, -1) @ trans_filtr
return result
%%timeit -r 7 -n 7
result = conv_direct_numpy_matmul(image, filtr)
930 µs ± 35.5 µs per loop (mean ± std. dev. of 7 runs, 7 loops each)
我们将程序从一开始的约 650 ms,经过 numpy 数乘与求和的引入到约 130 ms,再是 einsum 的引入到约 15 ms,最终依靠矩阵乘法提升到了 1 ms。这是约 600 倍的效率提升!但若只考虑并行的增益,那么效率提升最多也只有 8 倍 (因为我们目前只开了 8 核并行)。我们明确地看到,即使浮点计算数 FLOP 相同,若使用不同的算法或库函数,就会产生完全不同的效果。
8.2.4. 七重循环的 Numba 实现#
我们最后指出,纯 Python 方式高效实现还有一种途径,即使用 Numba。Numba 通过 LLVM (应用于各种高效能编译器的技术),实现纯 Python 代码的编译;其执行效率与 C/C++ 代码类似。我们不妨尝试一下,如果抛开 Python 语言本身的包袱,这段代码能有多快?
@nb.jit("float32[:,:,:,::1](float32[:,:,:,::1], float32[:,:,:,::1])", nopython=True, parallel=True)
def conv_direct_numba_7loops(image, filtr):
# === preparation ===
N, IC, IH, IW = image.shape
OC = filtr.shape[0]
OH, OW = IH - 2, IW - 2
result = np.zeros(( N, OC, OH, OW), dtype=np.float32)
# === direct algorithm ===
for i in nb.prange(N): # batch size [parallelized]
for k in range(OC): # out channel
for x in range(OH): # out height
for y in range(OW): # out width
for c in range(IC): # input channel
for u in range(3): # kernel width
for v in range(3): # kernel height
result[i, k, x, y] += image[i, c, x+u, y+v] * filtr[k, c, u, v]
return result
%%timeit -r 7 -n 7
result_ref = conv_direct_numba_7loops(image, filtr)
361 µs ± 69.9 µs per loop (mean ± std. dev. of 7 runs, 7 loops each)
说来可能不信,Numba 的速度到了 400 µs 级别。它相比于 Python 的七重循环实现,在算法相同的情况下,效率提升了 1500 倍!如此大的效率提升,多少有其偶然性。总结来说,Python 难以做到但 Numba 或编译语言可以实现的是
Numba 实现中,我们对分批数量 \(N\) 作简单并行。我们目前开了 8 核并行,因此效率提升也可能有 8 倍左右。
Numba 的实现相当于 C/C++ 编译语言了。对于 x86-64 架构,许多浮点计算在比较激进的编译指令 (譬如
-O3,-march) 会自动“向量化”(vectorized) 地进行;譬如 AVX-512 指令集可以一次性对 16 个浮点数作加法或乘法。因此,效率最大可以提升 16 倍;但很多时候能达到 4 倍就已经很令人满意了。AVX 中还单独设“乘积累加”(Fused Multiply Add/Accumulate) 运算,即本来要分两次执行的加法与乘法运算放在一次执行。卷积问题完美契合这个运算,因此还能获得 2 倍额外加速。
AVX (或其子集 SSE) 依靠向量化指令,对循环也能加速。
当前问题的输入图像、卷积核、输出图像都可以储存在 L2 cache 中。或许 Numba 对 cache 的处理要比 NumPy 好一些。
说不清楚的其它原因都归到 Python 的语言包袱吧 ≥ω≤
但同时也要说明,一旦卷积问题变大,图像、卷积核无法存入 L2 cache 时,这个算法会立即失败。在下面的测评环节就能看出端倪。
关于 AVX 指令集的一些操作,我们还会在第二篇文档中作展开。
8.3. 库函数介绍与初步性能测评#
8.3.1. 简化的实际问题:VGG16 conv(3.2)#
为了考察较为现实的网络效率,同时介绍各个库函数实现,我们先取 VGG16[2] 的一层网络 conv(3.2) 作为这一节的讨论对象。该网络还是有一点点挑战性的。其
图像大小 \(H_\mathrm{in} = W_\mathrm{in} = 56\);
输入、输出通道数 \(C_\mathrm{in} = C_\mathrm{out} = 256\);
每批图像数量为 \(N = 8\)。
image = np.random.random(( 8, 256, 56, 56)).astype('f') * 255
filtr = np.random.random((256, 256, 3, 3)).astype('f')
8.3.2. 效率测评量标:GFLOPs#
为了测评程序的效率,我们需要了解卷积过程的运算数量 (FLoating point OPeration, FLOP),以及当前程序的执行速度 (Giga-FLOP/sec 或 GFLOPs)。
计算 FLOP 的方式很简单。首先,这是一个简单张量缩并过程[3]。我们看到等式左边作为输出图像的 \(Y_{i,k,x,y}\),它有四个角标,其维度分别对应 \(N, C_\mathrm{out}, H_\mathrm{out}, W_\mathrm{out}\);而等式右边被求和的角标为 \(c, u, v\),分别对应 \(C_\mathrm{in}, K_\mathrm{H}=3, K_\mathrm{W}=3\)。同时,该式同时需要进行乘法与加法;假若算机的浮点乘法与加法运算效率相同[4],那么 FLOP 还需要乘以 2 (其 1 是一次加法、其 1 是一次乘法)。但需要注意的是,分批数量 \(N\) 与网络参数无关,因此要将其去除。最终的 FLOP 计算式为
def get_FLOP(inp: CNNInput):
return 18 * inp.OC * inp.OH * inp.OW * inp.IC
CNNInput.get_FLOP = get_FLOP
CNNInput(image, filtr).get_FLOP()
3439853568
即 VGG16 conv(3.2) 的 Giga-FLOP 或 GFLOP 数是 3.44。
我们可以使用下面折叠代码的函数 evaluate_GFLOPs,给出网络的参数、浮点运算数、以及当前实现下的程序效率。GFLOP 与执行时间都除去了分批数量 \(N\) 的贡献。
Show code cell content
def evaluate_GFLOPs(image, filtr, cnn, loops=10, preloops=3, flag_print=True):
inp = CNNInput(image, filtr)
flop = inp.get_FLOP()
if flag_print:
print("--- (N,IC,IH,IW,OC): ({:3d}, {:3d}, {:3d}, {:3d}, {:3d}); GFLOP : {:9.3f}".format(
inp.N, inp.IC, inp.IH, inp.IW, inp.OC, flop / 1000**3))
tlist = []
for _ in range(preloops):
cnn(image, filtr)
for _ in range(loops):
t0 = time.time(); cnn(image, filtr); tlist.append(time.time() - t0)
trun, tstd = np.sum(tlist), np.std(tlist)
time_ms = trun / loops / inp.N * 1000
time_std = tstd / inp.N * 1000
gflops = flop / time_ms / 1000**2
if flag_print:
print("--- ms/run/batch: {:9.3f} ± {:<7.3f} ; GFLOP/sec: {:9.3f}".format(time_ms, time_std, gflops))
return flop, time_ms, gflops
譬如对于 NumPy 的矩阵乘法方案,其执行时间大约在 70 ms 左右,对应程序效率大约是 50 GFLOPs 或 GFLOP/sec。
evaluate_GFLOPs(image, filtr, conv_direct_numpy_matmul);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 60.285 ± 1.836 ; GFLOP/sec: 57.060
8.3.3. 真实环境的卷积效率 (1):Python 实现#
我们先看看我们的纯 Python 程序效率。
即使使用了 NumPy 的四重循环方法,耗时还是太长,要跑 8 sec。VGG16 可是有 16 层啊,要每层都是这效率,那总耗时是 \(8 \times 16 = 128\) sec。用这种卷积神经网络做自动驾驶,那这就好比车开在路上,撞死了一个孩子之后要花两分钟才能反应过来。写出这种代码的人可以去枪毙两分钟。如果 Tezla 公司采用了这种代码,那这个公司不可能倒闭:它连能倒闭的资本都不会有 (手动狗头)。
evaluate_GFLOPs(image, filtr, conv_direct_numpy_4loops, loops=1, preloops=0);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 6594.200 ± 0.000 ; GFLOP/sec: 0.522
同样是七重循环,若用 Numba 进行编译加速会快许多,但仍然远远不达标:
evaluate_GFLOPs(image, filtr, conv_direct_numba_7loops, loops=3, preloops=1);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 234.823 ± 0.250 ; GFLOP/sec: 14.649
如果 Tezla 电动车以 100 km/h (28 m/sec) 的速度开在路上,发现 150 m 前有一小孩横穿马路 (高速路行车距离一般是 100 m、故障标志需放在 150 m 开外)。一般汽车在 100 km/h 下的紧急制动距离是 42 m。如果 Tezla 看到前面小孩,需要 0.3 sec 反应过来,那么就因算法延迟额外地增加了 \(0.3 \times 28 = 8.4\) m 的制动距离。需要指出这才只是 VGG16 网络的一层;如果全部 16 层都是这个效率,那总制动距离就变成 \(8.4 \times 16 + 28 = 162.4 > 150\) m。拯救生命挑战 大失败!
利用
np.einsum的效率会有明显提升:
evaluate_GFLOPs(image, filtr, conv_direct_numpy_einsum);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 82.997 ± 0.588 ; GFLOP/sec: 41.446
使用矩阵乘法的效率会更高:
evaluate_GFLOPs(image, filtr, conv_direct_numpy_matmul);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 57.045 ± 0.507 ; GFLOP/sec: 60.300
不过需要指出,即使用 NumPy 程序确实可以拯救小孩的生命,但因卷积网络导致的额外制动距离仍然有约 30 m。
真的是因为 Python,所以效率低下吗?不全然是。
首先,简单的纯 Python 实现,效率到这里我想已经是极限了。我相信仍然有可以提升的空间,譬如在复杂算法下,使用 Numba 或许能在手动调整算法后进一步加速。但 Numba 对性能微调的要求较高,因此想要写出真正高效的程序,非常困难。事实上,我在写这份文档时尝试过 Numba 的实现,但并未成功。
我们以前看到过,在小型问题中,Numba 的实现效率奇高;但为何一到 VGG16 conv(3.2) 就如此糟糕呢?
这是因为一旦图像、卷积核变大后,就无法在 L2 或 L3 cache、而要在主内存 (Dynamic Random Access Memory) 中储存这些张量;而 DRAM 的索引效率是低得恐怖的。程序看起来一直在 800% CPU 高速运转,也没有浪费任何浮点运算,但实际上却一直在忙着从主内存索取数据。
这是影响程序效率的最关键因素,但并非不可避免。通过缓存友好 (cache aware/friendly) 的编程方式,这种问题是可以避免的。我们会在以后的文档提及这个问题。
这不意味着 Python 一无所是。事实上,上述 Python 效率低下的原因应该是代码并非完全缓存友好 (但涉及矩阵计算的部分是 NumPy 调用 MKL 库的,这部分效率有保证)。如果随便写一个 C/C++ 程序,那会跟这里的 Numba 实现一样,效率也不见得高。我们马上就会看到。
8.3.4. 真实环境的卷积效率 (2):最简单的 C/C++ 实现#
这里作为一个 baseline,我们考察下述最简单的 C 程序 (driver.c 下的 naive_conv 函数)。它通过简单的七重循环实现,并且对于分批数 \(N\) 作简单并行 (与我们先前的 Numba 实现相同)。它抛弃了 Python 的所有包袱,并且优化选项几乎是最高的 (-O3 -march=native),或许因此其效率比算法完全一致的 Numba 效率要高。但即使如此,其实现效率远不如上述的 Python/NumPy。可见在这个问题中,缓存友好的编程方式是多么重要。
我们用 ctypes 调用该函数并考察其效率。
clib_winograd_f6x3 = np.ctypeslib.load_library("libwinograd_f6x3.so", ".")
def conv_direct_c_naive(image, filtr):
inp = CNNInput(image, filtr)
result = np.empty(inp.dim_result).astype('f')
clib_winograd_f6x3.naive_conv(
image.ctypes.data_as(ctypes.c_void_p),
filtr.ctypes.data_as(ctypes.c_void_p),
result.ctypes.data_as(ctypes.c_void_p),
ctypes.c_int(inp.N), ctypes.c_int(inp.IC),
ctypes.c_int(inp.IH), ctypes.c_int(inp.IW), ctypes.c_int(inp.OC))
return result
evaluate_GFLOPs(image, filtr, conv_direct_c_naive, loops=3, preloops=1);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 144.460 ± 0.148 ; GFLOP/sec: 23.812
8.3.5. 真实环境的卷积效率 (3):库函数与我们的程序#
我们这里需要经常用到函数签名相同的 C 程序,因此先作下述程序定义。
def conv_c_API(clib):
def inner(image, filtr):
inp = CNNInput(image, filtr)
result = np.empty(inp.dim_result).astype('f')
clib.winconv(
image.ctypes.data_as(ctypes.c_void_p),
ctypes.c_int(inp.IH), ctypes.c_int(inp.IW), ctypes.c_int(inp.IC),
filtr.ctypes.data_as(ctypes.c_void_p),
ctypes.c_int(inp.OC), ctypes.c_int(inp.N),
result.ctypes.data_as(ctypes.c_void_p))
return result
return inner
Intel oneDNN 是开源库;它需要通过 C/C++ 实现。下面是 Direct 卷积 (直接卷积,即上文提到的原理) 实现。
clib_direct_oneDNN = np.ctypeslib.load_library("libdnnl_direct.so", ".")
conv_direct_oneDNN = conv_c_API(clib_direct_oneDNN)
evaluate_GFLOPs(image, filtr, conv_direct_oneDNN, loops=100, preloops=10);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 3.724 ± 0.158 ; GFLOP/sec: 923.752
Intel oneDNN 还提供了 Winograd 卷积实现。若不考虑机器精度损失,Winograd 卷积与 Direct 卷积的实现结果完全相同。但与上面提到的种种优化算法或方法有本质上的不同:Winograd 卷积是降低了实际运算 FLOP 的算法。该算法有其适用范围与限制,因此并不一定有明显的速度提升,甚至可能不升反降。Winograd 算法会是下两篇文档的主要议题。这里所用的 GFLOP/sec 是有效 GFLOP 即 Direct 卷积的浮点运算数,而非 Winograd 卷积实际的浮点运算数。Intel oneDNN 实现的 Winograd 应是 \(F(2, 3)\) 或 \(F(4, 3)\)。
clib_winograd_oneDNN = np.ctypeslib.load_library("libdnnl_winograd.so", ".")
conv_winograd_oneDNN = conv_c_API(clib_winograd_oneDNN)
evaluate_GFLOPs(image, filtr, conv_winograd_oneDNN, loops=100, preloops=10);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 3.938 ± 0.049 ; GFLOP/sec: 873.397
我们自己编写的初赛程序偶尔能比 Intel oneDNN 快一些。它是一个相对比较简单的,实现了 Winograd 算法的程序。我们实现的 Winograd 是 \(F(6, 3)\)。
clib_winograd_f6x3 = np.ctypeslib.load_library("libwinograd_f6x3.so", ".")
conv_winograd_f6x3 = conv_c_API(clib_winograd_f6x3)
evaluate_GFLOPs(image, filtr, conv_winograd_f6x3, loops=100, preloops=10);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 3.708 ± 0.167 ; GFLOP/sec: 927.607
PyTorch 作为最流行的机器学习框架之一,也提供了非常简单直观的底层卷积函数。PyTorch 会依据实际情形选择算法,可能是 Winograd 也可能是 Direct。注意在效率测评过程中,必须要将反向传播过程关闭 (
torch.set_grad_enabled)。我们可以同时用下述函数给出 CPU 与 GPU 效率。需要说明的是,对于 PyTorch-GPU 情形,GPU 显卡内存与 DRAM 的通讯时间很大,不可忽略,如果所有计算都在 GPU 中进行,则 GFLOP/sec 会高到离谱。因此下面的代码会自 CPU 读取输入图像。
def conv_pytorch(device, filtr):
IC, OC = filtr.shape[:2]
torch_layer = torch.nn.Conv2d(IC, OC, 3, device=device)
torch_layer.load_state_dict({"weight": torch.tensor(filtr), "bias": torch.zeros(OC)})
def inner_func(image, filtr):
result = torch_layer(torch.tensor(image, device=device)).cpu()
return result
return inner_func
evaluate_GFLOPs(image, filtr, conv_pytorch("cpu", filtr), loops=100);
--- (N,IC,IH,IW,OC): ( 8, 256, 56, 56, 256); GFLOP : 3.440
--- ms/run/batch: 2.677 ± 0.039 ; GFLOP/sec: 1284.805
# execuate this code if gpu is available
# evaluate_GFLOPs(image, filtr, conv_pytorch("cuda", filtr), loops=10);
总地来说,我们可以看出,对于当前的问题而言,任何一个实用的 C/C++ 程序实现,都比 NumPy 实现能快上 15 倍。这才能完美地完成 拯救生命大挑战 !
不过囿于一些我自己也不了解的技术问题,使用 NumPy/ctypes 调用 C 程序,有时无法完全达到纯 C 程序的效率。这对实际应用可能影响不大,但对测评结果会有影响。因此,我们不在这里作更详尽的测评。在第三篇文档中,我们会完全讨论 C 代码,而不使用 Python。
我们都知道,若单论 NumPy 处理矩阵计算,其实效率与库函数实现没有多大差别。到底什么影响了卷积的实现效率呢?我们会在以后的文档中,对初赛工作作说明,从而可以一窥高效库函数的实现中,开发者可能会考虑到的问题。